
In this paper, we introduce Splatt3R, a pose-free, feed-forward method for in-the-wild 3D reconstruction and novel view synthesis from stereo pairs. Given uncalibrated natural images, Splatt3R can predict 3D Gaussian Splats without requiring any camera parameters, or depth information. For generalizability, we build Splatt3R upon a ``foundation'' 3D geometry reconstruction method, MASt3R, by extending it to deal with both 3D structure and appearance. Specifically, unlike the original MASt3R which reconstructs only 3D point clouds, we predict the additional Gaussian attributes required to construct a Gaussian primitive for each point. Hence, unlike other novel view synthesis methods, Splatt3R is first trained by optimizing the 3D point cloud's geometry loss and then the novel view synthesis objective. By doing this, we avoid the local minima present in training 3D Gaussian Splats from stereo views. We also propose a novel loss masking strategy that we empirically find is critical for strong performance on extrapolated viewpoints. We train Splatt3R on the ScanNet++ dataset and demonstrate excellent generalisation to uncalibrated, in-the-wild images. Splatt3R can reconstruct scenes at 4FPS at 512 x 512 resolution, and the resultant splats can be rendered in real-time.
Following the spirit of MASt3R, we show that a simple modification to their architecture, alongside a well-chosen training loss, is sufficient to achieve strong novel view synthesis results. We encode each image simultaneously using a vision transformer encoder, then pass them to a transformer decoder which performs cross-attention between each image. Normally, MASt3R has two prediction heads, one that predicts pixel-aligned 3D points and confidences, and a second which is used for feature matching. We introduce a third head to predict covariances (parameterized by rotation quaternions and scales), spherical harmonics, opacities and mean offsets for each point. This allows us to construct a complete Gaussian primitive for each pixel, which we can then render for novel view synthesis. During training, we only train the Gaussian prediction head, relying on a pre-trained MASt3R model for the other parameters.
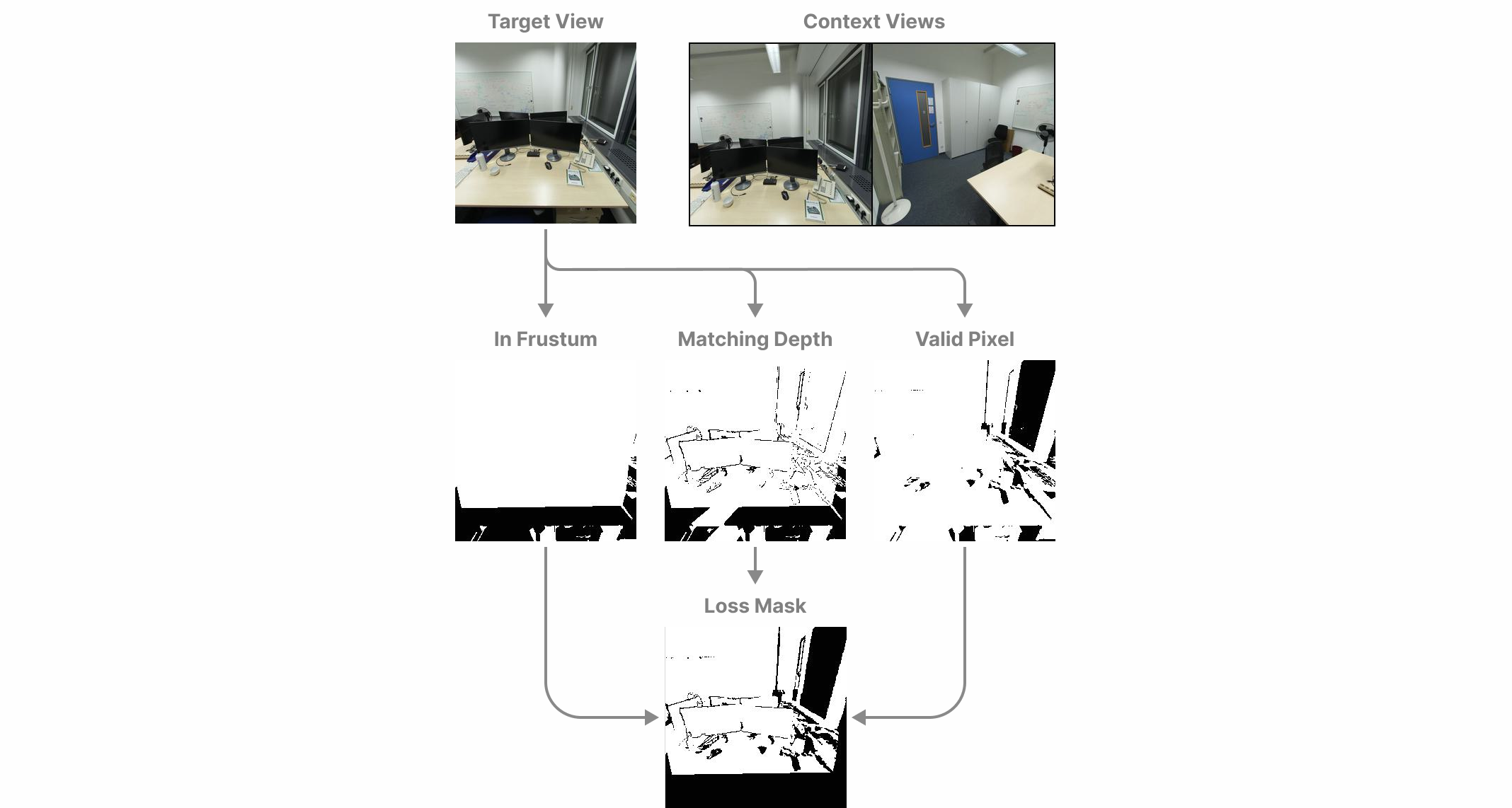
To optimize our Gaussian parameter predictions, we supervise novel view renderings of the predicted scene. During training, each sample consists of two input 'context' images which we use to reconstruct the scene, and a number of posed 'target' images which we use to calculate rendering loss. Some of these target images may contain regions of the scene that were not visible to the two context views due to being obscured, or outside of their frustums. To address this, we only supervise regions of our renderings which contain pixels that have direct correspondences to one of the pixels in the context images. This allows us to supervise our renderings from viewpoints that are not necessarily an interpolation between the two input images.


@article{smart2024splatt3r,
title={Splatt3R: Zero-shot Gaussian Splatting from Uncalibrated Image Pairs},
author={Brandon Smart and Chuanxia Zheng and Iro Laina and Victor Adrian Prisacariu},
year={2024},
eprint={2408.13912},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2408.13912},
}